ACCV 2022 Paper (Accepted as Oral)
Adriano Fragomeni, Michael Wray, Dima Damen
University of Bristol
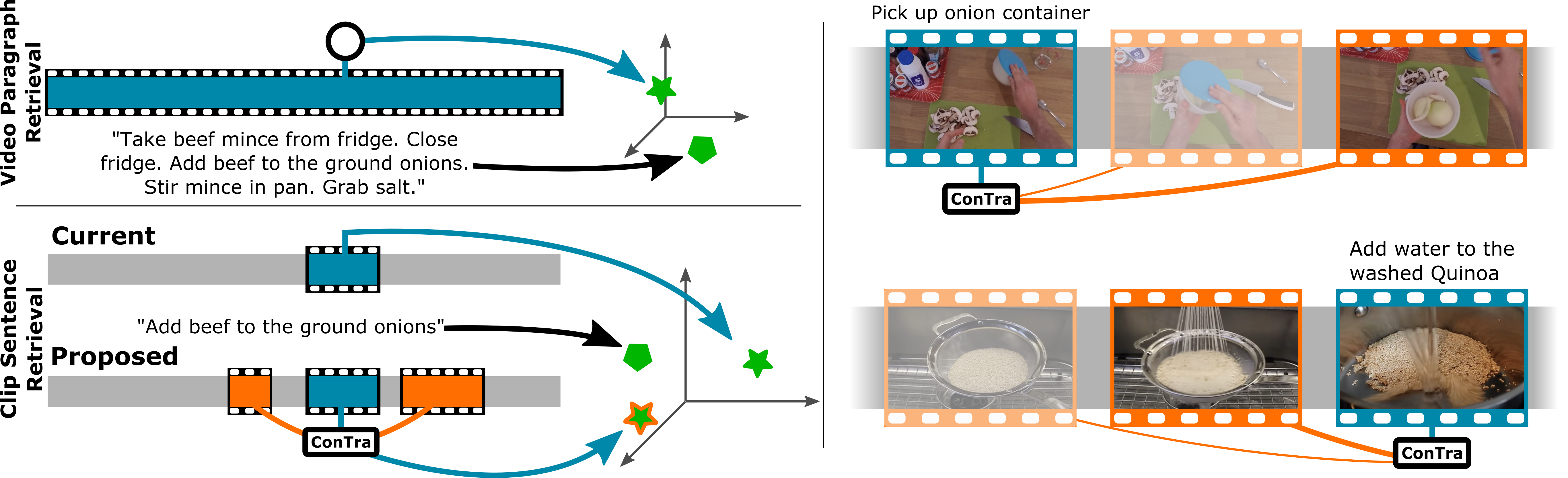 Left: We compare video-paragraph retrieval (top) to current and proposed clip-sentence retrieval (bottom) in long videos. In ConTra, we propose to attend to local context of neighbouring clips. Right: Examples where ConTra can enrich the clip representation from next/previous clips, observing the onion (top) or that the quinoa has already been washed (bottom). Line thickness/brightness represents attention weights.
Left: We compare video-paragraph retrieval (top) to current and proposed clip-sentence retrieval (bottom) in long videos. In ConTra, we propose to attend to local context of neighbouring clips. Right: Examples where ConTra can enrich the clip representation from next/previous clips, observing the onion (top) or that the quinoa has already been washed (bottom). Line thickness/brightness represents attention weights.
Abstract
In this paper, we re-examine the task of cross-modal clip-sentence retrieval, where the clip is part of a longer untrimmed video. When the clip is short or visually ambiguous, knowledge of its local temporal context (i.e. surrounding video segments) can be used to improve the retrieval performance. We propose Context Transformer (ConTra); an encoder architecture that models the interaction between a video clip and its local temporal context in order to enhance its embedded representations. Importantly, we supervise the context transformer using contrastive losses in the cross-modal embedding space. We explore context transformers for video and text modalities. Results consistently demonstrate improved performance on three datasets: YouCook2, EPIC-KITCHENS and a clip-sentence version of ActivityNet Captions. Exhaustive ablation studies and context analysis show the efficacy of the proposed method.
Video
Paper
Bibtex
@inproceedings{fragomeni2022ACCV,
author = {Fragomeni, Adriano and Wray, Michael and Damen, Dima},
title = {ConTra: ({C}on)text ({T}ra)nsformer for Cross-Modal Video Retrieval},
booktitle = {Proceedings of the Asian Conference on Computer Vision (ACCV)},
year = {2022}
}
Github
Acknowledgement
This work used public dataset and was supported by EPSRC UMPIRE (EP/T004991/1) and Visual AI (EP/T028572/1).