BMVC 2025 Paper
Adriano Fragomeni, Dima Damen, Michael Wray
University of Bristol
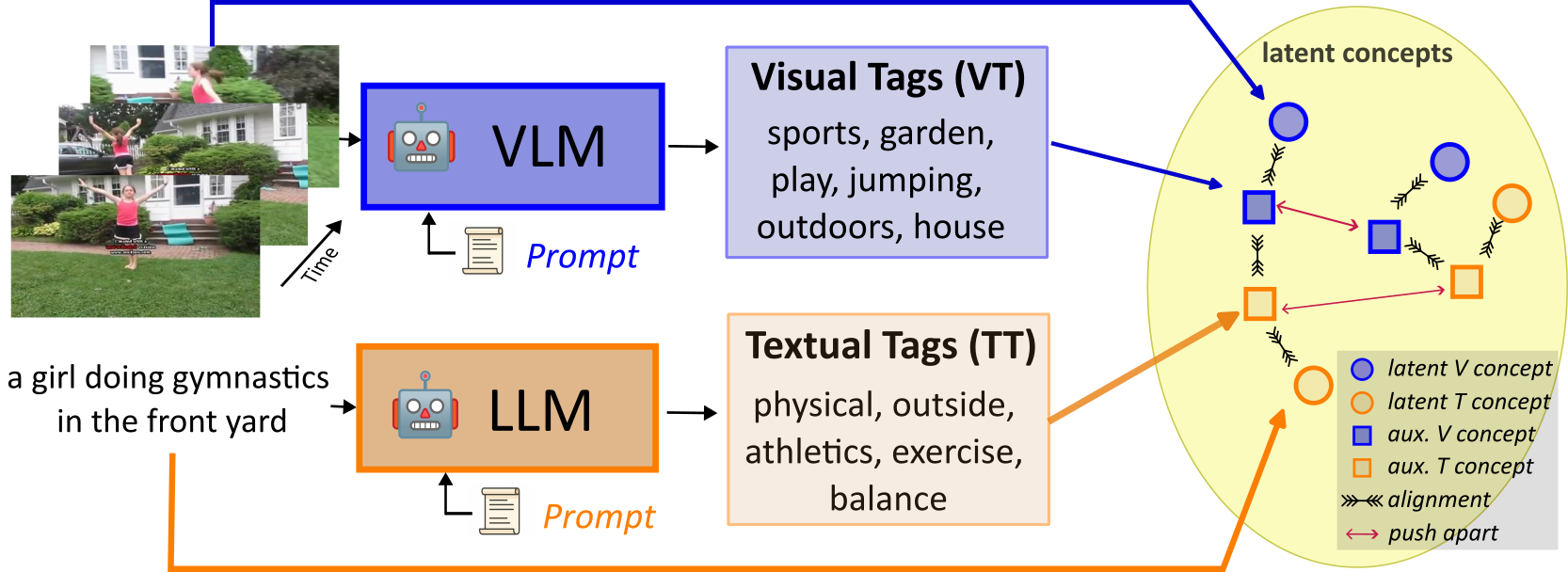 We propose to leverage modality-specific tags to enhance cross-modal video retrieval. Tags are extracted from both videos by Vision-Language Models (VLM) and texts by Large Language Models (LLM) using prompts designed to generate tags for each modality. For example, sports and physical tags can help align this video and its caption.
We propose to leverage modality-specific tags to enhance cross-modal video retrieval. Tags are extracted from both videos by Vision-Language Models (VLM) and texts by Large Language Models (LLM) using prompts designed to generate tags for each modality. For example, sports and physical tags can help align this video and its caption.
Abstract
Video retrieval requires aligning visual content with corresponding natural language descriptions. In this paper, we introduce Modality Auxiliary Concepts for Video Retrieval (MAC-VR), a novel approach that leverages modality-specific tags – automatically extracted from foundation models – to enhance video retrieval. We propose to align modalities in a latent space, along with learning and aligning auxiliary latent concepts derived from the features of a video and its corresponding caption. We introduce these auxiliary concepts to improve the alignment of visual and textual latent concepts, allowing concepts to be distinguished from one another. We conduct extensive experiments on six diverse datasets: two different splits of MSR-VTT, DiDeMo, TGIF, Charades and YouCook2. The experimental results consistently demonstrate that modality-specific tags improve cross-modal alignment, outperforming current state-of-the-art methods across three datasets and performing comparably or better across others.
Paper
Bibtex
@inproceedings{fragomeni2025BMVC,
author = {Fragomeni, Adriano and Damen, Dima and Wray, Michael},
title = {Leveraging Modality Tags for Enhanced Cross-Modal Video Retrieval},
booktitle = {British Machine Vision Conference (BMVC)},
year = {2025}
}
Github
Acknowledgement
This work used public datasets and was supported by EPSRC Fellowship UMPIRE (EP/T004991/1) and EPSRC Program Grant Visual AI (EP/T028572/1).